
Researchers using DARPA grant to dig out of deluge of data

U.S. intelligence agencies take in a tremendous amount of data from these sources and more every single day. Some of the data is conflicting. Other bits are unrelated. Their job is to comb through it all for details that, when added together, create a clear image of what is actually happening.
It’s a huge effort that CU Boulder researchers are attempting to make easier through artificial intelligence and natural language processing.
Their project is funded by the Defense Advanced Research Projects Agency (DARPA) at $2.7 million over four years. Professor Martha Palmer is the principal investigator and Professor James Martin and Assistant Professor Christoffer Heckman are co-investigators. All three are based in the Computer Science Department in the College of Engineering and Applied Science, while Palmer is also based in the Linguistics Department in the College of Arts and Sciences.
The project is part of the Active Interpretation of Disparate Alternatives — or AIDA — program at DARPA. That program aims to create a technology that would search video, text and still images from a variety of sources, aggregating and mapping pieces of information into a coherent storyline free of bias. It would then create multiple hypotheses about what the information is showing for further review by analysts.
Palmer said the project is one year in and that the analysis system works in three phases. The first phase looks at all the public and classified information available in its original form and context. The findings are then passed “over the wall” to the second phase for further examination and identification of multiple sources that are all talking about the same people and events, with the hope of resolving ambiguity and increasing accuracy of predictions. This second phase can’t review the original source documents from the first phase.
“The third phase is where the system looks seriously at different interpretations and decides which one has the most weight or confidence,” Palmer said. “A user could then ask questions about the interpretations to get more information before making their decisions.”
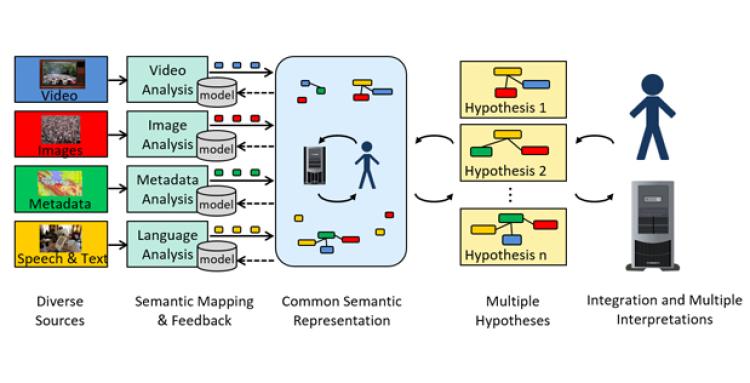
Palmer said the idea was to build a large knowledge base of “things” that are discussed frequently — world political leaders or tanks, for example. The machine would then begin linking them together by seeing which words appear in similar contexts or near each other frequently. To do this, the team is using a technique called multi-modal vector representations as they build a network that can be applied to different media sources.
“As soon as a new piece of information comes in, you try to match it to an entry in that knowledge base,” she said. “Then decide if it is saying the same thing over and over, or are you getting different information. Then paying more attention if that is the case.”
Heckman, a member of the Autonomous Systems Interdisciplinary Research Theme in the college, said this balance between autonomous systems and natural language is an interesting aspect of the project. In language, there is a clear difference between an office chair and a toy chair because of the context and connotations. There are ways to differentiate the two using computer vision to look at size, for instance. But getting to that context is one of the main challenges of the project, especially when pulling from different media sources.
Heckman said the goal is to get the computer vision and natural language processing communities closer together in terms of techniques and approach.
“It’s great that the communities of autonomous systems and natural language processing — two strong communities here at CU — are starting to talk with each other and pursue joint ventures with one another,” Heckman said. “I feel like this is just the first step in a long road, and I hope we can continue to pursue projects that the government or industry have that will move us in these directions.”
The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of DARPA or the U.S. Government. This material is based on research sponsored by DARPA under agreement number FA8750-18- 2-0016. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon.