
Publication
 We present our Robotic Agentic Platform for Intelligent Disassembly (RAPID), designed to investigate perception-driven manipulation, flexible automation, and AI-assisted robot programming in realistic recycling scenarios. The system integrates a gantry-mounted industrial manipulator, RGB-D perception, and an automated nut-running tool for fastener removal on a full-scale EV battery pack.
We present our Robotic Agentic Platform for Intelligent Disassembly (RAPID), designed to investigate perception-driven manipulation, flexible automation, and AI-assisted robot programming in realistic recycling scenarios. The system integrates a gantry-mounted industrial manipulator, RGB-D perception, and an automated nut-running tool for fastener removal on a full-scale EV battery pack. We contribute three improvements to the Inspire RH56DFX to transform it from a black-box device to a research tool: (1) hardware characterization (force calibration, latency, and overshoot), (2) a sim2real validated MuJoCo model for analytical width-to-grasp planning, and (3) a hybrid, closed-loop speed-force grasp controller. We validate these components on peg-in-hole insertion, achieving 65% success and outperforming a wrist-force-only baseline of 10% and on 300 grasps across 15 physically diverse objects, achieving 87% success and outperforming plan-free grasps and learned grasps.
We contribute three improvements to the Inspire RH56DFX to transform it from a black-box device to a research tool: (1) hardware characterization (force calibration, latency, and overshoot), (2) a sim2real validated MuJoCo model for analytical width-to-grasp planning, and (3) a hybrid, closed-loop speed-force grasp controller. We validate these components on peg-in-hole insertion, achieving 65% success and outperforming a wrist-force-only baseline of 10% and on 300 grasps across 15 physically diverse objects, achieving 87% success and outperforming plan-free grasps and learned grasps. We present a bimanual mobile manipulator built on the open-source XLeRobot with integrated onboard compute for less than $1300. Key contributions include: (1) optimized mechanical design maximizing stiffness-to-weight ratio, (2) a Tri-Bus power topology isolating compute from motor-induced voltage transients, and (3) embedded autonomy using NVIDIA Jetson Orin Nano for untethered operation. The platform enables teleoperation, autonomous SLAM navigation, and vision-based manipulation without external dependencies, providing a low-cost alternative for research and education in robotics and robot learning.
We present a bimanual mobile manipulator built on the open-source XLeRobot with integrated onboard compute for less than $1300. Key contributions include: (1) optimized mechanical design maximizing stiffness-to-weight ratio, (2) a Tri-Bus power topology isolating compute from motor-induced voltage transients, and (3) embedded autonomy using NVIDIA Jetson Orin Nano for untethered operation. The platform enables teleoperation, autonomous SLAM navigation, and vision-based manipulation without external dependencies, providing a low-cost alternative for research and education in robotics and robot learning. Maintaining balance under external hand forces is critical for humanoid bimanual manipulation, where interaction forces propagate through the kinematic chain and constrain the feasible manipulation envelope. We propose FAME, a force-adaptive reinforcement learning framework that conditions a standing policy on a learned latent context encoding upper-body joint configuration and bimanual interaction forces.
Maintaining balance under external hand forces is critical for humanoid bimanual manipulation, where interaction forces propagate through the kinematic chain and constrain the feasible manipulation envelope. We propose FAME, a force-adaptive reinforcement learning framework that conditions a standing policy on a learned latent context encoding upper-body joint configuration and bimanual interaction forces. Humans learn how and when to apply forces in the world via a complex physiological and psychological learning process. Attempting to replicate this in vision-language models (VLMs) presents two challenges: VLMs can produce harmful behavior, which is particularly dangerous for VLM-controlled robots which interact with the world, but imposing behavioral safeguards can limit their functional and ethical extents. We conduct two case studies on safeguarding VLMs which generate forceful robotic motion, finding that safeguards reduce both harmful and helpful behavior involving contact-rich manipulation of human body parts. Then, we discuss the key implication of this result--that value alignment may impede desirable robot capabilities--for model evaluation and robot learning.
Humans learn how and when to apply forces in the world via a complex physiological and psychological learning process. Attempting to replicate this in vision-language models (VLMs) presents two challenges: VLMs can produce harmful behavior, which is particularly dangerous for VLM-controlled robots which interact with the world, but imposing behavioral safeguards can limit their functional and ethical extents. We conduct two case studies on safeguarding VLMs which generate forceful robotic motion, finding that safeguards reduce both harmful and helpful behavior involving contact-rich manipulation of human body parts. Then, we discuss the key implication of this result--that value alignment may impede desirable robot capabilities--for model evaluation and robot learning. Vision language models (VLMs) exhibit vast knowledge of the physical world, including intuition of physical and spatial properties, affordances, and motion. With fine-tuning, VLMs can also natively produce robot trajectories. We demonstrate that eliciting wrenches, not trajectories, allows VLMs to explicitly reason about forces and leads to zero-shot generalization in a series of manipulation tasks without pretraining.
Vision language models (VLMs) exhibit vast knowledge of the physical world, including intuition of physical and spatial properties, affordances, and motion. With fine-tuning, VLMs can also natively produce robot trajectories. We demonstrate that eliciting wrenches, not trajectories, allows VLMs to explicitly reason about forces and leads to zero-shot generalization in a series of manipulation tasks without pretraining. This article reviews contemporary methods for integrating force, including both proprioception and tactile sensing, in robot manipulation policy learning. We conduct a comparative analysis on various approaches for sensing force, data collection, behavior cloning, tactile representation learning, and low-level robot control.
This article reviews contemporary methods for integrating force, including both proprioception and tactile sensing, in robot manipulation policy learning. We conduct a comparative analysis on various approaches for sensing force, data collection, behavior cloning, tactile representation learning, and low-level robot control.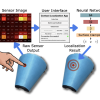 Estimating the location of contact is a primary function of artificial tactile sensing apparatuses that perceive the environment through touch. Existing contactlocalization methods use flat geometry and uniform sensor distributions as a simplifying
Estimating the location of contact is a primary function of artificial tactile sensing apparatuses that perceive the environment through touch. Existing contactlocalization methods use flat geometry and uniform sensor distributions as a simplifying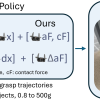 Robot trajectories used for learning end-to-end robot policies typically contain end-effector and gripper position, workspace images, and language. Policies learned from such trajectories are unsuitable for delicate grasping, which require tightly
Robot trajectories used for learning end-to-end robot policies typically contain end-effector and gripper position, workspace images, and language. Policies learned from such trajectories are unsuitable for delicate grasping, which require tightly Large language models (LLMs) can provide rich physical descriptions of most worldly objects, allowing robots to achieve more informed and capable grasping. We leverage LLMs’ common sense physical reasoning and code-writing abilities to infer an
Large language models (LLMs) can provide rich physical descriptions of most worldly objects, allowing robots to achieve more informed and capable grasping. We leverage LLMs’ common sense physical reasoning and code-writing abilities to infer an