Using mixed effects models to quantify dependency among repeated measures
Course Topics
Data may exhibit dependencies for many reasons. If a patient’s medical condition is measured across several time points, it seems unlikely that these measurements are totally unrelated. Educational studies may survey several students in the same classroom, and those students may perform similarly due to the common elements of their training. If the river level is higher than average today, there is a good chance that it will be higher than average tomorrow as well. How does one properly account for such dependencies when analyzing data?
Most basic statistical techniques assume independence among data points. Data do not depend on one another if knowledge of one data point’s outcome would not influence the outcome of another point prior to observation. However, many common study designs violate the assumption of independence. By statistically accounting for dependencies among data points, the researcher can enrich their understanding and more effectively quantify observed uncertainty in their study.
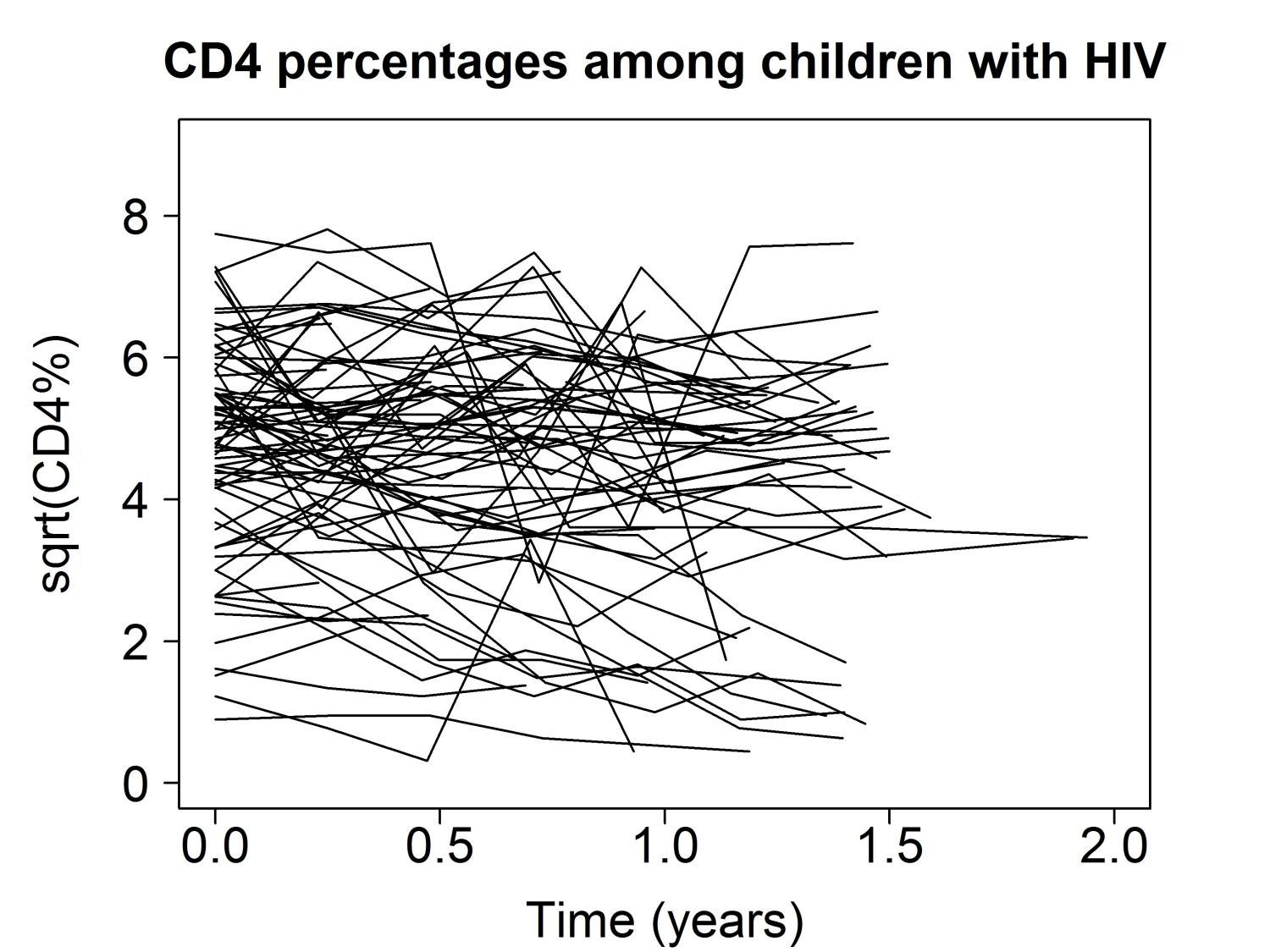
This short course will describe mixed effects models, which are a member of the broader class of hierarchical models. The course will use data from a study of white blood cell percentages among children with HIV, and another that longitudinally follows maple trees over time. Upon completing the course, attendees will (a) be able to describe a mixed effects model including specification of fixed and random effects, (b) describe variance components and intraclass correlation, (c) implement software to fit mixed effects models, and (d) qualitatively contextualize the results of this analytic approach.
Links:
http://www.stat.columbia.edu/~gelman/arm/