
Multivariate Clustering Analysis
Course Topics
Multivariate analysis in statistics is a set of useful methods for analyzing data when there are more than one variable under consideration. Multivariate analysis techniques may be used for several purposes, such as dimension reduction, clustering, or classification. The primary goal of this short course is to help researchers who want to understand multivariate data and explore multivariate analysis tools.
This short course concentrates on clustering techniques. The goal of clustering analysis is to establish a set of meaningful groups of similar objects by investigating relationships between objects. For example, if you have data from customers, you may segment customers into clusters based on their buying habits and their demographical characteristics. Then, you can use clustering results to custom tailor your marketing efforts.
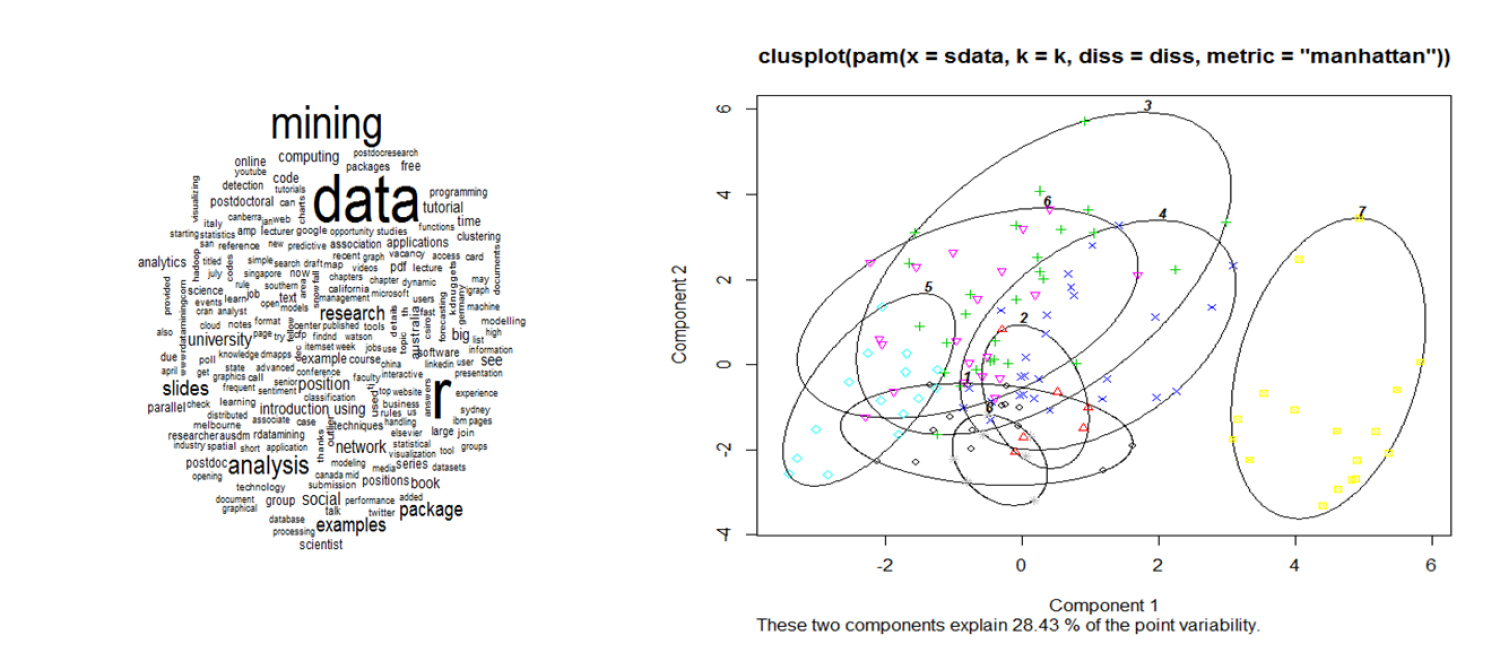
This short course includes lecture and computer laboratory components. In the lecture component, distance measures measuring distance between clusters are briefly reviewed. Then, several popular clustering techniques such as Agglomerative hierarchical clustering, K-means clustering algorithm, Partitioning around medoids, and Density-based clustering will be introduced. Also, how to visualize the clustering solutions and how to evaluate the quality of clustering results will be discussed. In the laboratory component, various clustering algorithm will be implemented using R on tweets data, which containing 340 tweets (http://www.rdatamining.com). This short course assumes basic R coding ability and familiarity with a normal distribution.
[video:https://vimeo.com/147466097]
LISA Short Course: Multivariate Clustering Analysis, Part I from LISA on Vimeo.
[video:https://vimeo.com/148275568]
LISA Short Course: Multivariate Clustering Analysis, Part II from LISA on Vimeo.